


時々難しい問題を投げかける、ロボットではないことを確認するためのreCAPTCHA、「階段のタイルをすべて選択してください」と問われましたが、階段らしき物が見当たりません。
1番上の行、左から2番目を選択したら正解だったみたいなのは #ナイショ。
CAPTCHA(キャプチャ)が、ロボットではない(人間である)ことの確認なのに対し、reCAPTCHA(リキャプチャ)は、CAPTCHAと同時に書籍の電子化に一役買っているのは #ナイショ。
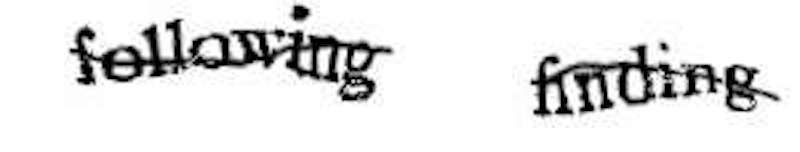
古い紙の本は、傷んでいたり汚れていたりして文字が読みにくくなっている。
OCRの技術が進んでもコンピュータでは文字としての判別が難しい。
それを、ロボットではないことの確認と称して人間に入力させて正しい文字を判断する。
この仕組み考えた人、天才じゃない #かしら?
フリー百科事典『ウィキペディア(Wikipedia)』
CAPTCHA(キャプチャ)は チャレンジ/レスポンス型テストの一種で、応答者がコンピュータでないことを確認するために使われる。
ウィキペディアにおいても、ログインしていない状態のユーザ(IPユーザー)が外部リンクを追加する際、スパム (メール)の防止のためこの種の認証が用いられる。外部リンクを追加しない場合にも濫用される。
この用語はカーネギーメロン大学のルイス・フォン・アン、マヌエル・ブラム、ニコラス・J・ホッパー、IBMのジョン・ラングフォードによって2000年に造られた。CAPTCHA という語は「completely automated public Turing test to tell computers and humans apart」(コンピュータと人間を区別する完全に自動化された公開チューリングテスト)のバクロニムである。
認知ソフトウェアに対抗するために難化が繰り返された結果、既に人間の認識が困難になるほど難化しており、本来の目的を果たせていない場合がある(「過剰な難化」の節を参照)。
reCAPTCHA(リキャプチャ)とは、ウェブサイトの制限エリアへのアクセスを試みるボットからサイトを防御するためCAPTCHAを利用するのと同時に、そのCAPTCHAに対する返答を紙の本のデジタル化に活かすシステムである。オリジナルは2007年にカーネギーメロン大学ピッツバーグ本校にて開発された。2009年9月16日にGoogleはこのテクノロジーを買い取っている。
現在reCAPTCHAはニューヨーク・タイムズが持つ記事アーカイブの電子化及びGoogle ブックスの書籍電子化に利用されている。前者は2009年の時点で、130年分を超えるという全記事のうち約20年分のデジタル化を2、3ヶ月で完了しており、残余は2011年末までの完了を目指していた。
reCAPTCHAは、OCRソフトウェアが読み取れなかった文字を画像として出力し、reCAPTCHAのデータを受信する各購読サイトへ向けてそれらを割り振る。購読サイトは、書籍デジタル化プロジェクトとは概ね無関係なサイトが多いが、これらの文字を含む画像を人間に差し出して、通常通りの認証手順の一部としてCAPTCHAの文字列を解読させる。そしてreCAPTCHAサービスは解答されたデータをデジタル化プロジェクトへ送信する。

